No, there is no such thing as a one-tailed p-value for an F-test.— R-Index (@R__INDEX) April 5, 2016
reported F(1,40)=3.72, p=.03; correct p=.06
use t-test for one-tailed.
I thought it would be useful to illustrate 1) why the default F-test is never ‘two-sided’ ,
2) why a one-sided F-test on two means is not possible, but a one-sided t-test for the same two means is possible, and 3) why
you can not halve p-values for F-tests with
more than 2 groups.
The F-value and
the t-value are related: t2 = F. This holds as long as the df1 = 1 (e.g., F(1, 100)) because in this case, two
groups are compared, and thus, the F-test
should logically equal a t-test. The critical t-value, squared, of a two-sided t-test
with a 5% error rate equals the F-value
of a F-test, which is always
one-sided, with a 5% error rate.
If you halve a p-value from an F-test (e.g., a p = 0.06 is reported as a ‘one-sided’ p = 0.03), you don’t end up with a directional F-test with a 5% error rate. It already was a directional F-test with a 5% error rate.
If you halve a p-value from an F-test (e.g., a p = 0.06 is reported as a ‘one-sided’ p = 0.03), you don’t end up with a directional F-test with a 5% error rate. It already was a directional F-test with a 5% error rate.
The reason is that t2
has no negative values. In a F-distribution,
all differences are values in the same direction. It’s like when you close a
book that was open: Where all pages were on both sides of the spine in the open
book (the t-test) all pages are on
one side of the spine in a F-test.
This is visualized in the figure below (see the R script below this post). The black curve is
an F(1,100)-distribution (did you know the F-distribution was named in honor of Fischer?). The light
blue area contains the F-values that
are extreme enough to lead to p-values
smaller than 0.05. The green curve is the right half of a t-distribution,
and the light green area contains t-values
high enough to return p-values
smaller than 0.05. This t-distribution
has a mirror image on the other side of 0 (not plotted).

The two curves connect at 1 because t2 = F, and 12
= 1. If we square the critical value for the two-sided t-test (t = 1.984), we
get the critical F-value (F = 3.936).
In the F-distribution, all extreme p-values are part of a single tail. In the t-distribution, only half of the extreme values are in the right tail. It is possible to use a t-test
instead of an F-test on the same means. With the t-test, you can easily separate the extreme values from differences in one direction, from the extreme values due to differences in the other direction, which is not possible in the F-test. When you switch from the F-test to the t-test, you can report a
one-sided p-value when comparing two
groups, as long as you decided to perform a one-sided test before looking at
the data (this doesn't seem likely in Dr R's tweet above!).
If the df1 is larger than 1 (for example, when more than 2
groups are compared), the F-test checks whether there are differences between multiple groups. Now, the relation
between the t-test and F-test no longer exists. It not possible to report a t-test instead of an F-test, and it is thus no longer possible to
report a p-value that is divided by
two.
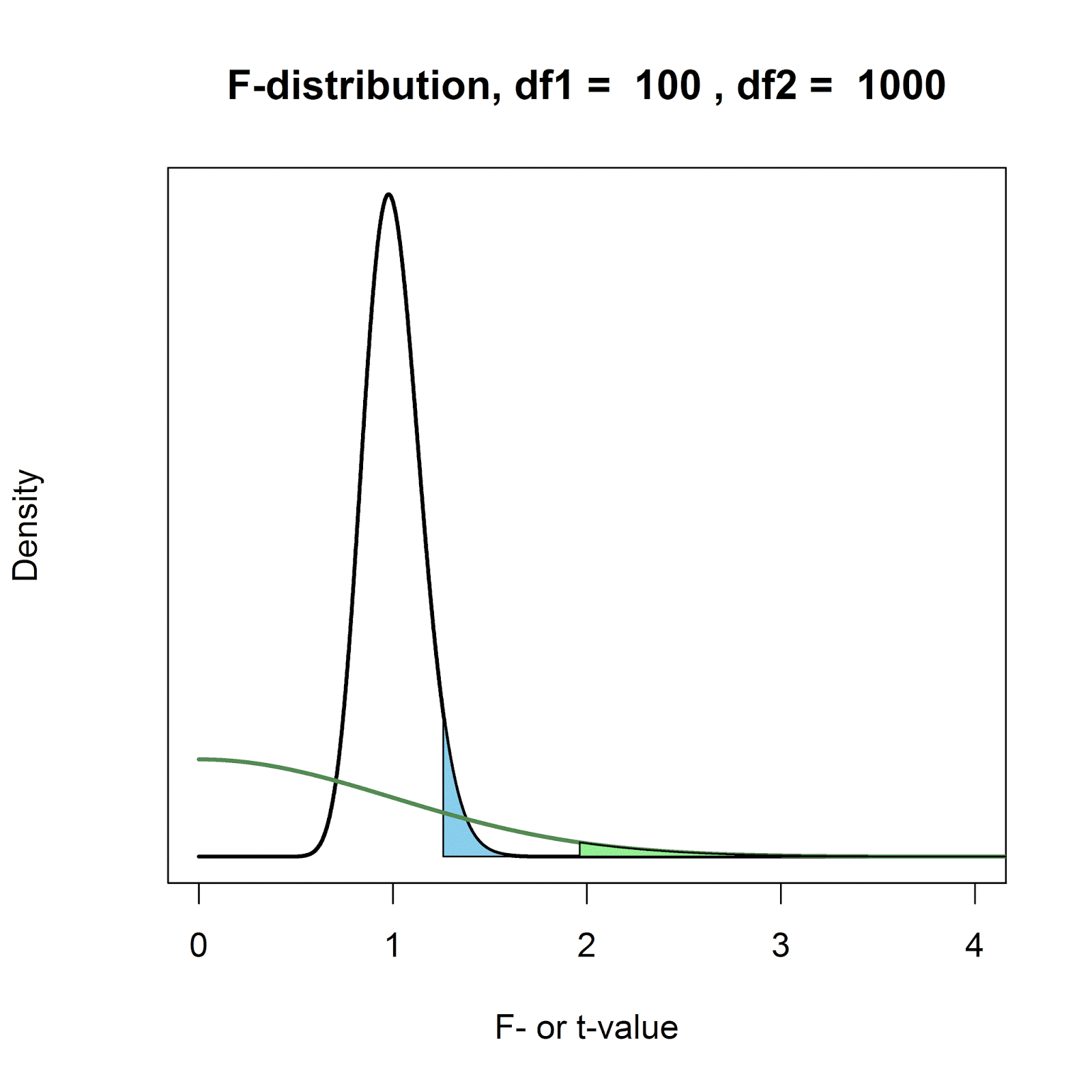
Remember that an F-test is the ratio of the mean squares variance estimate of effects plus error, divided by the mean squared error variance alone. If this ratio is 1, there is no effect, and if the ratio is sufficiently larger than one, there is an effect - which is why we are only interested in the larger than 1 tail. The larger the degrees of freedom, the closer the F-distribution lies around 1. In the graph below, we see the F(100, 1000)-distribution and a t-distribution with df = 1000. It's a very clear (albeit extreme) illustration of the difference between a F-distribution and the t-distribution.
Remember that an F-test is the ratio of the mean squares variance estimate of effects plus error, divided by the mean squared error variance alone. If this ratio is 1, there is no effect, and if the ratio is sufficiently larger than one, there is an effect - which is why we are only interested in the larger than 1 tail. The larger the degrees of freedom, the closer the F-distribution lies around 1. In the graph below, we see the F(100, 1000)-distribution and a t-distribution with df = 1000. It's a very clear (albeit extreme) illustration of the difference between a F-distribution and the t-distribution.
{kind=link}
To conclude: When comparing two groups, an F-test is always one-sided, but you can report a (more powerful) one-sided t-test - as long as you decided this before looking at the data. When comparing more than two groups, and the df1 is larger than 1, it makes no sense to halve the p-value (although you can always choose an alpha level of 10% when designing your study).
This was the subject of an argument between the two examiners of my PhD thesis (during my viva) ... There is arguably a one sided F tests that looks at F values that are too small to be chance (F below 1) - I have a paper on it somewhere. Essentially you are testing whether there is less variability than chance. I'm not sure it is often that useful in practice as it seems to rely on strong continuity assumptions and require large samples.
ReplyDeleteHi Thom! Yes, see my sneaky use of 'default' F-test, and how we are interested in whether the F-value is larger than 1. It is possible to test for the other tail. Uli Schimack mentioned on Twitter something about how Fischer might have used it to examine Mendel's data - but I couldn't find anything in detail on it, and decided it wasn't part of the 80% I talk about on this blog ;)
DeleteHi Daniel,
ReplyDeleteInteresting question. I might be pointing out the obvious here, but:
1) The F-test is one-sided in the sense that we only look at the extreme values on one side *of the F distribution*, but:
2) It is not one-sided in the sense of a one-sided t-test, where one is only looking at differences *between the actual sample means* that go in a particular direction.
Informally, this is fairly clear from the fact that a two-sided t-test and an F-test with 1 df have exactly the same p values.
In a bit more detail:
The p value from an F-test provides the probability of observing a sum of squared differences between the group means and the grand mean that is as great or larger than that observed. Because the differences from the grand mean are squared, the direction of the differences between sample means are ignored.
So in the sense that everyday researchers probably care about most (i.e., with respect to the actual hypothesis tested), an F test probably isn't best described as "one-sided".
(I wouldn't exactly call it two-tailed either of course, given that there can be many different sample means, any pair of which can differ from one another in either direction!)
Or, one could say the analysis evaluates whether the error we make taking the grand mean as a model for the data (model H0) is equal to the error we make if we assume a mean for each group (model H1) is needed to describe the data.
DeleteThen the two tailed test becomes rather silly: "we predict the group mean model is better AND worse than the grand mean model at the same time"
Hi Daniel,
ReplyDeleteI haven't read that Fisher did this with Mendel's work using F tests, but he certainly did with chi squared, see for example https://digital.library.adelaide.edu.au/dspace/bitstream/2440/15123/1/144.pdf . Quite a bit more on this in the Mendel article on Wikipedia. Chi squared is like F in that the statistic can't be negative.
Once again, nice post.
ReplyDeleteIncidentally, there is a context in which you employ a "proper two-sided F-test" (i.e. you look at both the left and right tail of the F-distribution): the variance ratio test.
If you have two populations, both normally distributed with unknown variance, and are interested in H0: sigma^2(A) = sigma^2(B) versus the two-sided alternative, the F-test is given by F = var(A)/var(B). Values in the left 2.5% of the distribution indicate that sigma^2(A) is smaller than sigma^2(B), the end of the right tail indicates the opposite.
Great that you clarified this.
ReplyDelete