I’m happy to announce my first R package ‘TOSTER’ for equivalence tests (but don’t worry, there is an old-fashioned spreadsheet as well).
In an earlier blog post I talked about equivalence tests. Sometimes
you perform a study where you might expect the effect is zero or very small. So
how can we conclude an effect is ‘zero or very small’? One approach is to
specify effect sizes we consider ‘not small’. For example, we might decide that
effects larger than d = 0.3 (or smaller than d = -0.3 in a two-sided t-test), are ‘not small’. Now, if
we observe an effect that falls between the two equivalence bounds of d = -0.3
and d = 0.3 we can act (in good old-fashioned Neyman-Pearson approach to statistical inferences) as if the effect is ‘zero or very small’. It might not be
exactly zero, but it is small enough. You can check out a great interactive visualization of
equivalence testing by RPsychologist.
We can use two one-sided tests to statistically reject
effects ≤
-0.3, and ≥
0.3. This is the basic idea of the TOST (two one-sided tests) equivalence
procedure. The idea is simple, and it is conceptually similar to the
traditional null-hypothesis test you probably use in your article to reject an effect of
zero. But where all statistics programs will allow you to perform a normal t-test, it is not yet that easy to perform a TOST equivalence test (Minitab is one exception).
But psychology really needs a way to show effects are too small to
matter (see ‘Why
most findings in psychology are statistically unfalsifiable’ by Richard Morey
and me). So I made a spreadsheet and R
package to perform the TOST procedure. The R package is available from CRAN, which
means you can install it using install.packages(“TOSTER”).
Let’s try a practical example (this is one of the examples from
the vignette
that comes with the R package).
Eskine (2013) showed that participants who had been exposed to
organic food were substantially harsher in their moral judgments relative to
those in the control condition (Cohen’s d =
0.81, 95% CI: [0.19, 1.45]). A replication by Moery & Calin-Jageman (2016,
Study 2) did not observe a significant effect (Control: n = 95, M = 5.25, SD =
0.95, Organic Food: n = 89, M = 5.22, SD = 0.83). The authors have used
Simonsohn’s recommendation to power their study so that they have 80% power to
detect an effect the original study had 33% power to detect. This is the same
as saying: We consider an effect to be ‘small’ when it is smaller than the effect size the original study
had 33% power to detect.
With n = 21 in each condition, Eskine (2013) had 33% to detect an
effect of d = 0.43. This is the effect the authors of the replication study designed their study to
detect. The original study had shown an effect of d = 0.81, and the authors
performing the replication decided that an effect size of d = 0.43 would be the
smallest effect size they will aim to detect with 80% power. So we can use this
effect size as the equivalence bound. We can use R to perform an equivalence
test:
install.packages("TOSTER")
library("TOSTER")
TOSTtwo(m1=5.25, m2=5.22, sd1=0.95, sd2=0.83, n1=95, n2=89, low_eqbound_d=-0.48, high_eqbound_d=0.48, alpha = 0.05, var.equal = TRUE)
Which gives us the following output:
TOST results:
t-value lower bound: 3.48 p-value lower bound: 0.0003
t-value upper bound: -3.03 p-value upper bound: 0.001
degrees of freedom : 182
Equivalence bounds (Cohen's d):
low eqbound: -0.48
high eqbound: 0.48
Equivalence bounds (raw scores):
low eqbound: -0.4291
high eqbound: 0.4291
TOST confidence interval:
lower bound 90% CI: -0.188
upper bound 90% CI: 0.248
NHST confidence interval:
lower bound 95% CI: -0.23
upper bound 95% CI: 0.29
Equivalence Test Result:
The equivalence test was significant, t(182) = -3.026, p = 0.00142, given equivalence bounds of -0.429 and 0.429 (on a raw scale) and an alpha of 0.05.
Null Hypothesis Test Result:
The null hypothesis test was non-significant, t(182) = 0.227, p = 0.820, given an alpha of 0.05.
Based on the equivalence test and the null-hypothesis test combined, we can conclude that the observed effect is statistically not different from zero and statistically equivalent to zero.You see, we are just using R like a fancy calculator, entering all the numbers in a single function. But I can understand if you are a bit intimidated by R. So, you can also fill in the same info in the spreadsheet (click picture to zoom):
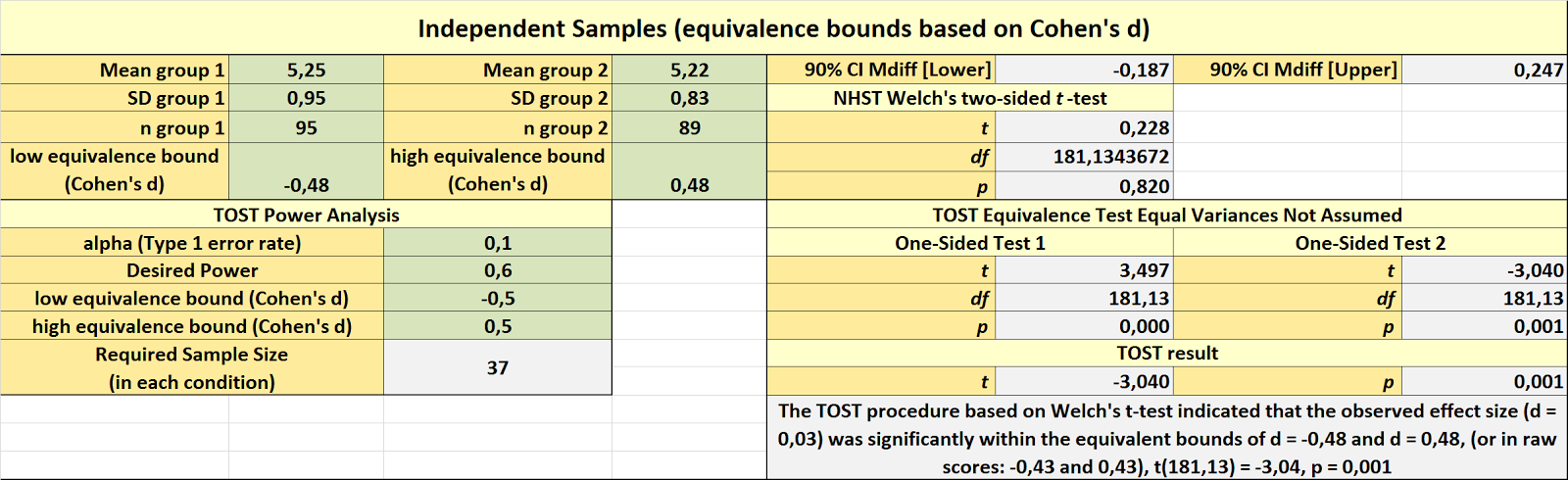
Using a TOST equivalence procedure with alpha = 0.05, and without assuming
equal variances (because when sample sizes are unequal, you
should report Welch’s t-test by default), we can reject effects larger than
d = 0.48: t(182) = -3.03, p = 0.001.
The R package also gives a graph, where you see the observed
mean difference (in raw scale units), the equivalence bounds (also in raw
scores), and the 90% and 95% CI. If the 90% CI does not include the equivalence
bounds, we can declare equivalence.

Moery and Calin-Jageman concluded from this study: “We again
found that food exposure has little to no effect on moral judgments” But what
is ‘little to no”? The equivalence test tells us the authors successfully rejected
effects of a size the original study had 33% power to reject. Instead of saying ‘little to no’ we can put a number on
the effect size we have rejected by performing an equivalence test.
If you want to read more about equivalence tests, including
how to perform them for one-sample t-tests,
dependent t-tests, correlations, or
meta-analyses, you can check out a practical primer on equivalence testing using the TOST procedure I've written. It's available as a pre-print on PsyArXiv. The R code is available on GitHub.
This looks really cool... I might be biased because I enjoyed seeing some of my own work as the example (thanks).
ReplyDeleteA couple of questions from a quick read:
* How does the TOST 90% CI relate to the NHST 95% CI? Meaning, if I recalculate the NHST CI at the 90% level, would it come out similar to the TOST CI? Is there any major difference in how they are interpreted?
* In the paper, Eileen and I reported the 95% CI for the standardized effect size (Cohen's d): d = -0.03, [-0.32, 0.26]. Again, for the purposes of the TOST test, we'd need a 90% CI. But otherwise is doing the TOST analysis similar to examining if the boundary is within this CI? Would it be right to say that any value outside this CI is non-equivalent? I feel like that's not quite the same, but I'm not understanding how.
One top-of-the-head suggestion might be to have the package give the CIs in terms of standardized effects, since that's how the boundary conditions for non-equivalence are specified...feels easier to then compare them back to the boundary. I'm not sure if that's trivial to implement or not.
Oh - and just wanted to point out a couple of things about the example study..the example study above is from what the paper labelled as Study 2, collected with MTurk participants. It was one of 3 replications conducted, the other two with live participants, and so the overall effect size obtained provided some pretty narrow boundaries on a plausible effect: d = 0.06, 95% CI[-0.14, 0.26]. These details are not at all essential to explaining this (cool) new R package... just wanted to point out that how we had approached estimating the boundaries for the proposed effect.
Nice work!
Hi, the TOST procedure is the same as using 90%CI - but for some conceptual differences, see the pre-print.
DeleteYou don't want to say values outside the 90% CI are not equivalent - because there you are testing against 0. See the pre-print for the explanation how studies can be significant AND equivalent.
Yes, the output could be in Cohen's d, but I carefully chose not to do this. You might not have noticed, but setting equivalence bounds in Cohen's d is actually the new thing in my implementation of equivalence tests. Just a tiny change, but it will make it more intuitive for psychologists. However, some people worry about using standardized effect sizes, and raw differences are easier to interpret, and arguably, it should be the goal to express all effects in raw scales. So, you can set the equivalence bounds in d, but I give feedback in raw scale units. But, if more people prefer CI around d, I might provide these as well in a future update.
Hiya Daniel,
ReplyDeleteSo there's something that puzzled me over the Christmas break and I wondered if you might want to weigh in. I noticed that on Twitter you've said a couple of supportive things about Neyman-Pearson testing, and it sounds like this is your preferred approach to significance testing?
The thing is, in my understanding of Neyman-Pearson testing (e.g., http://journals.sagepub.com/doi/abs/10.1177/0959354312465483), you *can* accept (and not just fail to reject) H0, provided that power is high and p > alpha. This stands in contrast to Fisherian NHST, where you can never accept or support H0.
In other words... it seems to me that equivalence testing is the solution to a problem that Neyman-Pearson testing doesn't actually have (well, if you have enough power anyway). There are complications of convention in the sense that the typical target Type 2 error rate is 20% whereas we might want it to be less than that if we want to provide convincing evidence for H0, but in principle... NP alone has the tools to support a null.
So anyhow: Is your understanding of NP testing different than mine? If not, are there pragmatic reasons why you think equivalence testing is necessary even for someone working in an NP framework?
Thanks so much for developing this package and thoroughly explaining its use in your paper! I've been using a homegrown function for the TOST, but hadn't taken into account using the Welch test when variances are unequal and I'm appreciative of your package/paper bringing this to my attention.
ReplyDeleteI looked through the code on GitHub and I was wondering why when var.equal=F you are using the root mean square standard deviation formula to set the equivalence boundaries since I believe this assumes equal sample sizes.
Hi Regis, yes, I discussed this online, but there is, as far as I know, no formula for Cohen's d for a Welch's test. So we are left with an unsatisfactory situation of having to standardize in a perhaps not ideal way, but I also would not know what is better. Can you email me about this - I'd love to chat more, and given your interest in the R code, you might have good ideas of how to improve this?
DeleteThank you for this! It has been very useful in a paper we are finalising. Quick question: is there a TOST equivalent for Likert-type data (e.g. sign rank test instead of t-test)? Would it be enough to convert likert scores to ranks?
ReplyDeleteHere something similar I have found: http://stats.stackexchange.com/questions/52897/equivalence-tests-for-non-normal-data
Enrico Glerean, www.glerean.com
Yes, it should be possible - either take the 90% CI approach, or use dedicated software: https://ncss-wpengine.netdna-ssl.com/wp-content/themes/ncss/pdf/Procedures/NCSS/Testing_Equivalence_with_Two_Independent_Samples.pdf - might program it into the package in the future!
DeleteThank you!!!
DeleteEnrico
Hi Daniel,
Deletethanks a lot for the package!
I have samples that are not normally distributed and they have different sizes so it would be great if you could clarify how I could perform the equivalence test using the 90% CI approach. I read that in R it's possible to use the wilcox.test to do that but I don't have completely clear how.
Thanks a lot.
Alessandro
Hi Daniel, is there any way to control for covariates using this package?
ReplyDeleteHi, no, there are no ANOVA functions yet. If it becomes popular, I might work out functions for it, or (even better) someone else might want to do that work.
DeleteAlright, thanks for your quick response!
DeleteThis comment has been removed by the author.
ReplyDeleteMaybe it's a stupid question, but why don't I get the same results when I use "TOSTtwo" and "dataTOSTtwo"?
ReplyDeleteHere the example code:
# Illustration of 1.5 sigma distibution difference
n <- 10
test_mean <- 20
test_sd <- 3
Biosimilar <- rnorm(n,test_mean,test_sd)
Reference <- rnorm(n,test_mean,test_sd)
equiv.margin <- sd(Reference)*1.5
Sample <- c(rep("Biosimilar",length(n)),
rep("Reference",length(n)))
Values <- c(Biosimilar,
Reference)
TOSTtwo(m1=mean(Biosimilar),
m2=mean(Reference),
sd1=sd(Biosimilar),
sd2=sd(Reference),
n1=length(Biosimilar),
n2=length(Reference),
low_eqbound_d=-1.5,
high_eqbound_d=1.5
)
df <- data.frame(Sample, Values)
dataTOSTtwo(df, deps="Values", group="Sample", var_equal = FALSE, low_eqbound = -1.5,
high_eqbound = 1.5, alpha = 0.05, desc = TRUE, plots = TRUE)
Tosttwo set bound in d a tostdata in raw. Please NO questions here. Horrible way to communicate. Send an email or use github.
DeleteHi Daniel,
ReplyDeleteThis might be a lame question, but your answer would be of immense help.
Can i conduct a equivalence test for a one-proportions test?
for example, i have binomial outcome variable from an experiment in which participants answered yes or no (example: yes=60, no = 40; N =100). Where p is proportions of people who answered yes. My hypothesis is:
H0: p=0.5
H1: p>0.5.
best, prasad
Thank you for the wonderful package.
ReplyDeleteIs there a good way to determine equivalence margins?
This comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDelete