When designing a study, you need to justify the sample size you aim to collect. If one of your goals is to observe a p-values lower than the alpha level you decided upon (e.g., 0.05), one justification for the sample size can be a power analysis. A power analysis tells you the probability of observing a statistically significant effect, based on a specific sample size, alpha level, and true effect size. At our department, people who use power as a sample size justification need to aim for 90% power if they want to get money from the department to collect data.
A power analysis is performed based on the
effect size you expect to observe. When you expect an effect with a Cohen’s d
of 0.5 in an independent two-tailed t-test,
and you use an alpha level of 0.05, you will have 90% power with 86
participants in each group. What this means, is that only 10% of the
distribution of effects sizes you can expect when d = 0.5 and n = 86 falls
below the critical value required to get a p < 0.05 in an independent
t-test.
In the figure below, the power analysis is
visualized by plotting the distribution of Cohen’s d given 86 participants per
group when the true effect size is 0 (or the null-hypothesis is true), and when
d = 0.5. The blue area is the Type 2 error rate (the probability of not finding
p < α, when there is a true effect).
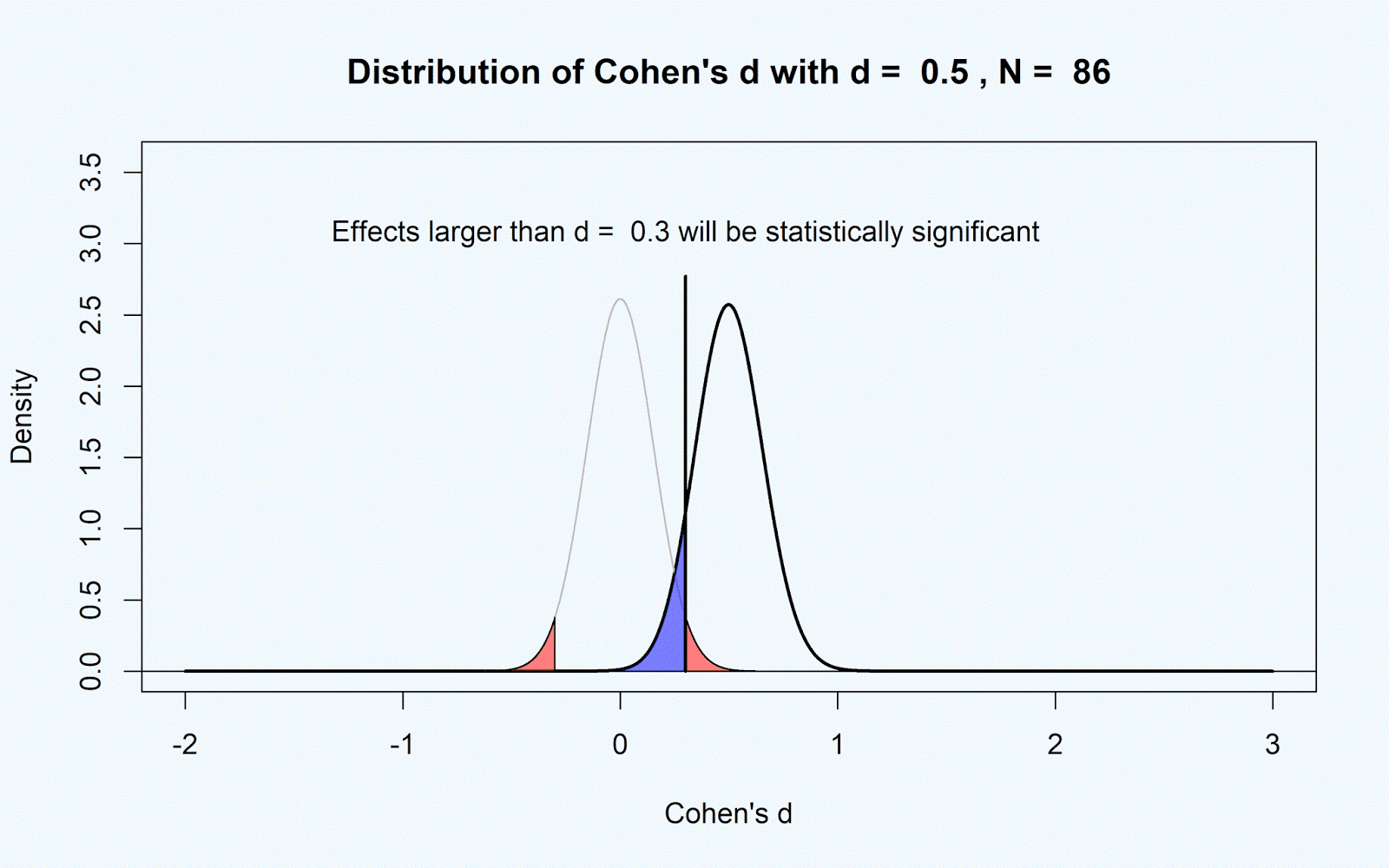
You’ve probably seen such graphs before
(indeed, G*power, widely used power analysis software, provides these graphs as
output). The only thing I have done is to transform the t-value distribution that is commonly used in these graphs, and
calculated the distribution for Cohen’s d. This is a straightforward
transformation, but instead of presenting the critical t-value the figure provides the critical d-value. I think people
find it easier to interpret d than t. Only t-tests which yield a t ≥ 1.974, or a d ≥ 0.30, will be statistically
significant. All effects smaller than d = 0.30 will never be statistically significant with 86 participants in each condition.
If you design a study where results will be
analyzed with an independent two-tailed t-test
with α = 0.05, the smallest true effect you can statistically detect is
determined exclusively by the sample size. The (unknown) true effect size only
determines how far to the right the distribution of d-values lies, and thus,
which percentage of effect sizes will be larger than the smallest effect size
of interest (and will be statistically significant – or the statistical power).
I think it is reasonable to assume that if
you decide to collect data for a study where you plan to perform a null-hypothesis significance test, you are not interested in effect sizes that will never be
statistically significant. If you design a study that has 90% power for a
medium effect of d = 0.5, the sample size you decide to use means effects smaller than d = 0.3 will never be
statistically significant. We can use this fact to infer what your smallest effect size of interest, or
SESOI (Lakens, 2014), will be. Unless you state otherwise, we can assume your SESOI is d
= 0.3, and any effects smaller than this effect size are considered too small
to be interesting. Obviously, you are free to explicitly state any effect
smaller than d = 0.5 or d = 0.4 is already too small to matter for theoretical
or practical purposes. But without such an explicit statement about what your
SESOI is, we can infer it from your power analysis.
This is useful. Researchers who use
null-hypothesis significance testing often only specify the effect they expect
when the null is true (d = 0), but not the smallest effect size that should
still be considered support for their theory when there is a true effect. This leads to a psychological
science that is unfalsifiable (Morey & Lakens,
under review).
Alternative approaches to determining what the smallest effect size of interest
is have recently been suggested. For example, Simonsohn (2015) suggested to set the smallest effect size of interest to 33% of the
effect size in the original study could detect. For example, if an original study used 20 participants per group, the smallest effect size of interest would be d = 0.49 (which is the effect size they had 33% power to detect with n = 20).
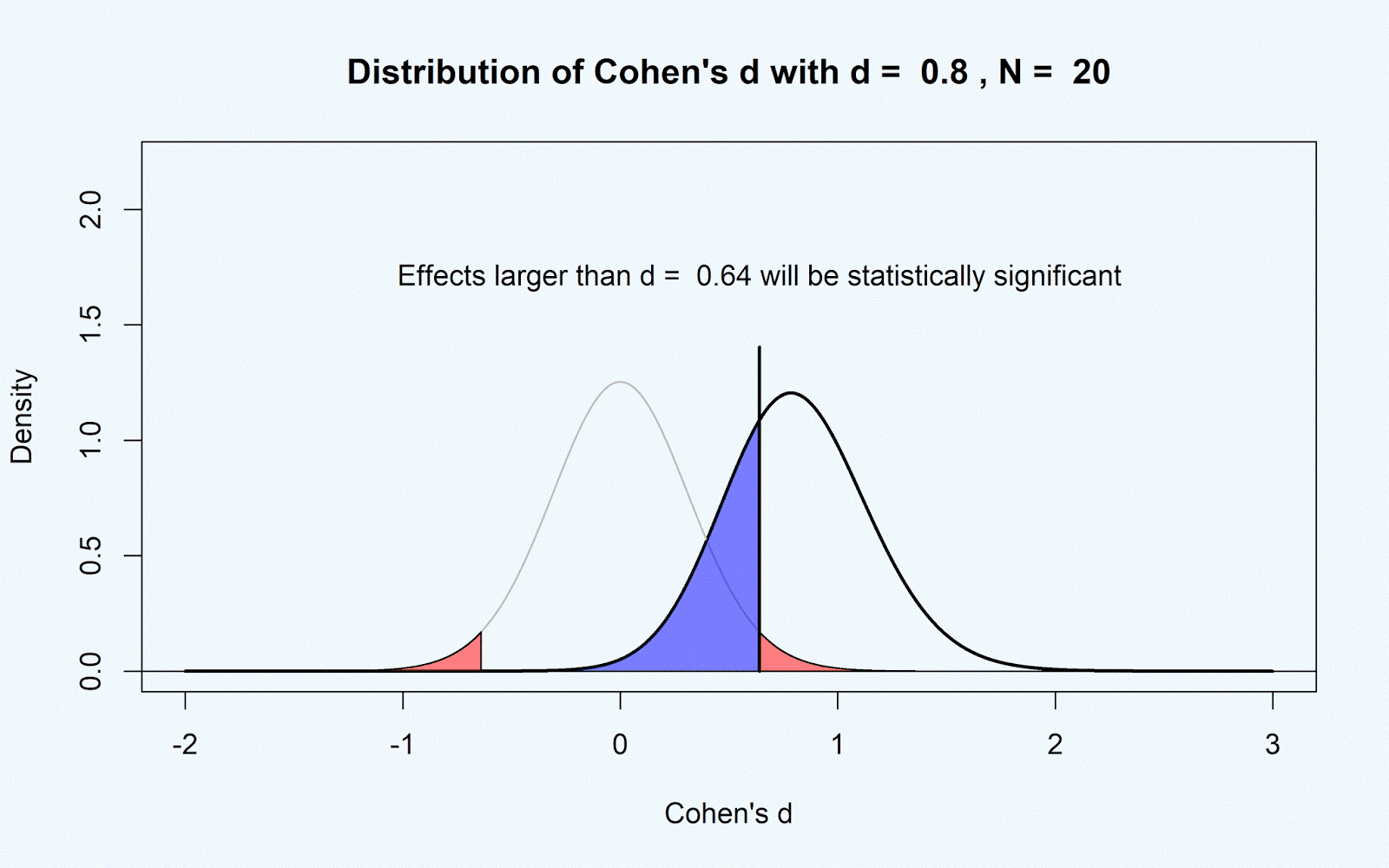
Let’s assume the original study used a sample size of n = 20 per group. The figure below shows that an observed effect size of d
= 0.8 would be statistically significant (d = 0.8 lies to the right of the
critical d-value), but that the critical d-value is d = 0.64. That means that
effects smaller than d = 0.64 would never be statistically significant in a
study with 20 participants per group in a between-subjects design. I think it makes more sense to assume the
smallest effect size of interest for researchers who design a study with n = 20
is d = 0.64, rather than d = 0.49.
The figures can be produced by a new Shiny app I created (the Shiny app also plots power curves and the p-value
distribution [they are not all visible on Shinyapps.org, but you can try HERE as long as bandwidth lasts, or just grab the code and app from GitHub] – I might discuss these figures in a future blog post). If you
have designed your next study, check the critical d-value to make sure that the
smallest effect size you care about, isn’t smaller than the critical effect
size you can actually detect. If you think smaller effects are interesting, but
you don’t have the resources, specify your SESOI explicitly in your article. You
can also use this specified smallest effect size of interest in an equivalence
test to statistically reject any effect large enough that you deem it
worthwhile (Lakens, 2017), which will help interpreting t-tests
where p > α. In
short, we really need to start specifying the effects we expect under the
alternative model, and if you don’t know where to start, your power analysis
might have been implicitly telling you what your smallest effect size of
interest is.
References
Lakens, D. (2014).
Performing high-powered studies efficiently with sequential analyses:
Sequential analyses. European Journal of Social Psychology, 44(7),
701–710. https://doi.org/10.1002/ejsp.2023
Lakens, D. (2017). Equivalence tests: A practical primer for t-tests, correlations, and meta-analyses. Social Psychological and Personality Science. https://doi.org/10.1177/1948550617697177
Morey, R. D., & Lakens, D. (under review). Why most of psychology is statistically unfalsifiable.
Simonsohn, U. (2015). Small Telescopes Detectability and the Evaluation of Replication Results. Psychological Science, 26(5), 559–569. https://doi.org/10.1177/0956797614567341